1.什么是深度分页?
答案:从100万商品信息中查询长沙地区售卖排名为的90001-90100位的100名商品的信息。
mysql 解决方案如下:
select * from product where localthion=’changsha’ order by sells limit 90001,90100;

如果你不假思索的提供了这么个解决方案,那么恭喜你,你马上会被打上不靠谱的标签。因为这个需要根据不同的场景做不同的优化。如果是对于面向C端用户进行翻页操作而产品上又必须要此功能的话,那只能通过mysql想办法提高性能。但也肯定不是以上办法。
解决: select * from product id in (select id from product where localtion=’changsha’ order by sells limit 90001,90100); 最好有联合索引ind_localtion_sells
言归正传,回到ES。对于ES来说,深度分页意味着什么呢?
深度分页案例:
1 | GET product/_search |
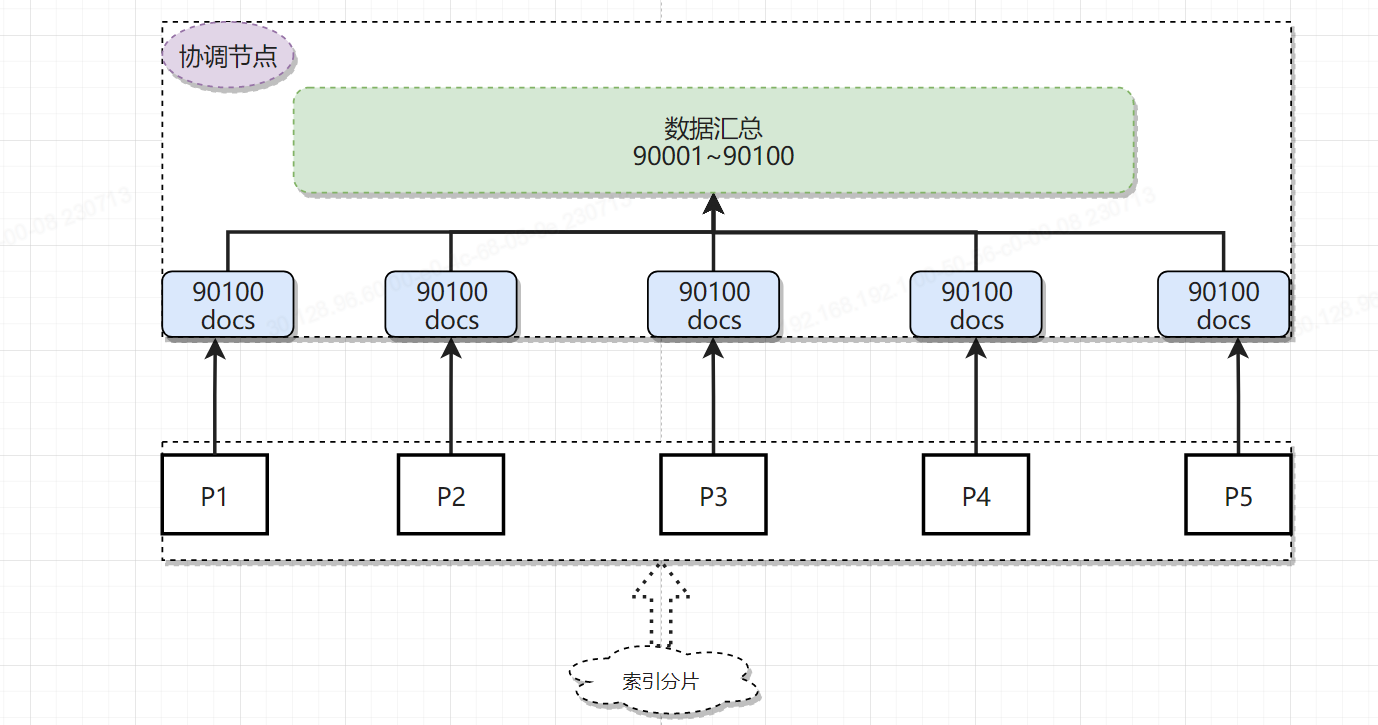
假设100万名商品信息被存放在一个product索引中,由于索引数据在写入是并无法判断在执行业务查询时的具体排序规则,因此排序是随机的。而由于ES的分片和数据分配策略为了提高数据在检索时的准确度,会把数据尽可能均匀的分布在不同的分片。假设此时我们有五个分片,每个分片中承载20万条有效数据。按照需求我们需要在热销产品中取90001到90100的一百名商品的信息,就要先按照售卖量进行倒序排列。然后按照page_size: 90100&page_index: 90001进行查询。即查询按照售卖量排序,第90001页的100个商品的信息。
对于mysql来说这种问题相对而言还好解决一些。因为数据库是单机,先按照把100万商品排序,然后从前90100条数据数据中取出第90001-90100条。即按照100为一页的第901页数据。
但是对于分布式系统来说这种深度分页的难度远比单机要大。不同于单机数据库,商品信息是被分散保存在每个分片中的,你无法保证要查询的这一百个商品信息一定都在某一个分片中,结果很有可能是存在于每个分片。换句话说,你从任意一个分片中取出的前90001个商品信息,都不一定是总商品的前90001。更不幸的是,唯一的解决办法是从每个分片中取出当前分片的前90100个商品信息,然后汇总成450500条数据再次排序,然后从排序后的这450500个商品信息中查询前90100的商品信息,此时才能保证一定是整个索引中的商品信息是前90100名。如果还不理解,我再举个例子用来类比:从保存了世界所有国家短跑运动员成绩的索引中查询短跑世界前三,每个国家类比为一个分片的数据,每个国家都会从国家内选出成绩最好的前三位参加最后的竞争,从每个国家选出的前三名放在一起再次选出前三名,此时才能保证是世界的前三名。
2.深度分页带来的问题
从上面案例中不难看出,每次有序的查询都会在每个分片中执行单独的查询,然后进行数据的二次排序,而这个二次排序的过程是发生在heap中的,也就是说当你单次查询的数量越大,那么堆内存中汇总的数据也就越多,对内存的压力也就越大。这里的单次查询的数据量取决于你查询的是第几条数据而不是查询了几条数据,比如你希望查询的是第10001-10100这一百条数据,但是ES必须将前10100全部取出进行二次查询。因此,如果查询的数据排序越靠后,就越容易导致OOM(Out Of Memory)情况的发生,频繁的深分页查询会导致频繁的FGC。 ES为了避免用户在不了解其内部原理的情况下而做出错误的操作,设置了一个阈值,即max_result_window,其默认值为10000,其作用是为了保护堆内存不被错误操作导致溢出。

当出现以上错误的时候,很多人第一反应是更改参数。诚然,调大这个参数可以立即解决当前问题。但是贸然的调大这个参数又会给ES埋下安全隐患。这个雷也许不会在你手里炸掉,但确很有可能会在对ES了解不是那么深的技术员手里炸掉。这个参数是ES官方设置的较为安全的参数。如果业务需要确实要调大的话,那也是是需要通过你的各项指标参数来衡量确定的,比如你用户量、数据量、物理内存的大小、分片的数量等等。通过监控数据和分析各项指标从而确定一个最佳值,并非越大越好。
3.深度分页问题的常见解决方案?
那么我们实际生产过程中到底怎么解决深度分页问题呢?拿mysql来说,通过先查询到深页里面的主键然后再去拿记录的方案可以很好的减轻数据库的压力。对于ES来说,也是这样的吗?回答问题前,我们先看一下业内搜索做的好的标杆是怎么解决这个问题的呢?
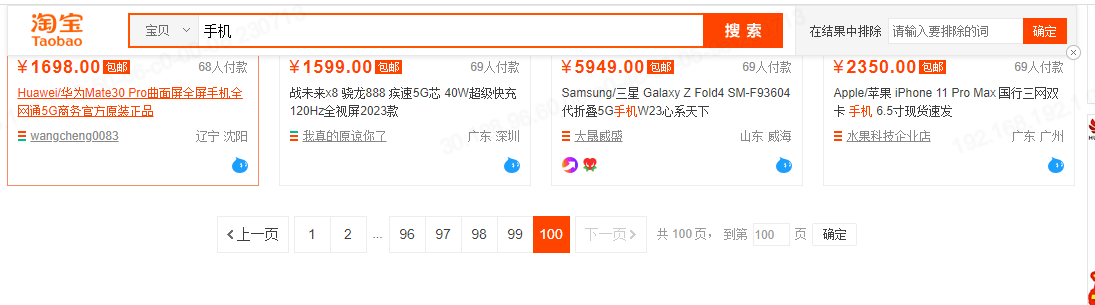
淘宝:
google:
这里可以看到一个有趣的现象,淘宝网上不管我们搜索什么内容,只要商品结果足够多,返回的商品列表都是仅展示前100页的数据,我们不难发现,其实召回的商品被“截断”了,不管你有多少,我都只允许你查询前100页,其实这本质和ES中的max_result_window作用是一样的,都是限制你去搜索更深页数的数据。google针对深度分页做的更为严格,直接在分页条中删除了“跳页”功能,其目的就是为了避免用户使用深度分页检索。看到这里的话估计大多数人心里估计就有答案了。怎么解决?不解决就是最好的解决…… 开个玩笑,还是需要针对特定的场景做优化
解决方案一:滚动查询:Scroll Search 注:此方案针对非C端用户,也就是说并发量不大的情况使用此方案
3.1.1 适合场景
请求中检索大量结果,即非“C端业务”场景
1 | GET <index>/_search?scroll=1m |
时间单位:
d |
Days |
|---|---|
h |
Hours |
m |
Minutes |
s |
Seconds |
ms |
Milliseconds |
micros |
Microseconds |
nanos |
Nanoseconds |
为了使用滚动,初始搜索请求应该scroll在查询字符串中指定参数,该 参数告诉 Elasticsearch 应该保持“搜索上下文”多长时间,例如?scroll=1m。结果如下:
1 | { |
上述请求的结果包含一个_scroll_id,应将其传递给scrollAPI 以检索下一批结果。
滚动返回在初始搜索请求时与搜索匹配的所有文档。它会忽略对这些文档的任何后续更改。该scroll_id标识一个搜索上下文它记录身边的一切Elasticsearch需要返回正确的文件。搜索上下文由初始请求创建,并由后续请求保持活动状态。
3.1.2 注意
- Scroll上下文的存活时间是滚动的,下次执行查询会刷新,也就是说,不需要足够长来处理所有数据,它只需要足够长来处理前一批结果。保持旧段处于活动状态意味着需要更多的磁盘空间和文件句柄。确保您已将节点配置为具有充足的空闲文件句柄。
- 为防止因打开过多Scrolls而导致的问题,不允许用户打开超过一定限制的Scrolls。默认情况下,打开Scrolls的最大数量为 500。此限制可以通过
search.max_open_scroll_context集群设置进行更新 。
3.1.3 清除滚动上下文
scroll超过超时后,搜索上下文会自动删除。然而,保持Scrolls打开是有代价的,因此一旦不再使用该clear-scrollAPI ,就应明确清除Scroll上下文
1 | #清除单个 |
解决方案二:
3.2 Search After
SearchAfter是一种动态指针的技术,每次查询都会携带上一次的排序值,这样下次取结果只需要从上次的位点继续扫数据,前提条件也是该字段是数值类型且设置了docValue。举个例子,假设”val_1”是数值类型的字段,然后使用Search接口查询时候添加Sort(“val_1”),那么response中可以拿到最后一条数据的”val_1”的值,,也就是response中sort字段的值,然后下次查询将该值放在query中的searchAfter参数中,下次查询就可以在上一次结果之后继续查询,如此反复,最后可以翻页很深,内存消耗相比size+from的方式降低了数倍。
例子:
1 | GET product/_search |
- 不支持向前搜索
- 每次只能向后搜索1页数据
- 适用于C端业务
总结:ES对于深度分页解决方案有两种。一种是Scroll Search,另外一种是Search After
scroll search : 可以分为初始化和遍历两部,初始化时将「所有符合搜索条件的搜索结果缓存起来(注意,这里只是缓存的doc_id,而并不是真的缓存了所有的文档数据,取数据是在fetch阶段完成的)」,可以想象成快照。
优点:快速、稳定
缺点:1.数据变更不会对结果上有变化。2.scoll过程中会segments暂时无法被merge
Search After:searchAfter参数中内存消耗相比size+from的方式降低了数倍。该方式效果类似于我们直接在bool查询中主动加一个rangeFilter
优点:1.可面向C端用户 2.相较而言比from size消耗低得多
缺点:1.不适合跳页 2.也不适合深度分页查询

